品牌型号:联想拯救者R7000
系统:Windows 10专业版
软件版本:Anaconda 3
在数据分析和机器学习领域,Anaconda是一个广泛使用的工具。不仅提供了Python和R的集成环境,还包含了大量常用库,方便开发人员进行数据处理和分析。在使用Anaconda时,一个重要的步骤就是如何导入数据集,尤其是CSV文件。本文将详细介绍Anaconda如何导入数据集,并讨论Anaconda怎么导入CSV文件,帮助你更高效的进行数据分析工作。
一、Anaconda如何导入数据集
Anaconda为用户提供了多种导入数据集的方法,主要可以通过内置的Jupyter Notebook或Spyder等工具来实现。在Anaconda环境中,可以使用Python内置的pandas包导入各种数据集格式,包括Excel、SQL数据库和CSV文件等。以下是一些常用的数据集导入方法:
1、使用Pandas库导入数据集
Pandas是Python中最常用的数据处理库之一,它能读取不同格式的数据集,并将其存储为DataFrame格式,方便后续的操作和分析。导入数据集的代码如下:
import pandas as pd
data=pd.read_csv("./data/credit_card.csv",encoding='gbk')
print("原数据的形状为",data.shape)
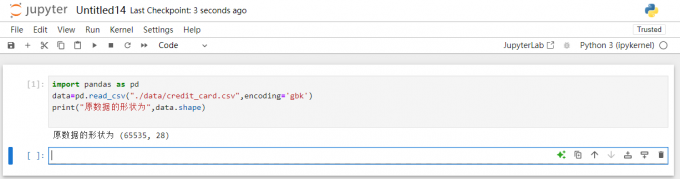
以上代码中,首先使用import pandas as pd导入Pandas库,然后使用pd.read_csv()函数读取CSV文件。读取的内容会被存储在变量data中,并输出date的形状。
2、使用Dask处理大型数据集
如果数据集规模较大,Pandas可能在内存中运行缓慢或无法处理。在这种情况下,可以选择使用Dask。Dask提供与Pandas类似的API,但具有分布式处理能力,能够处理超出内存的数据集。以下是使用Dask读取CSV文件的代码示例:
import dask.dataframe as dd
# 读取CSV文件
data = dd.read_csv('./data/credit_card.csv',encoding='gbk')
print(data.head)
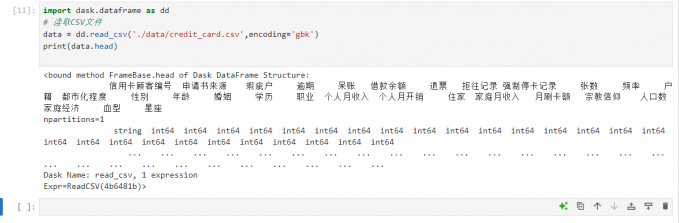
使用Dask,可以读取并处理大型数据集,从而在数据量较大的情况下依然能够流畅地进行数据分析。
二、Anaconda怎么导入CSV文件
CSV文件是一种常见的数据存储格式,适合用于存储结构化数据。在Anaconda中,导入CSV文件非常简单。以下是使用Anaconda导入CSV文件的详细步骤。
1、使用Jupyter Notebook导入CSV文件
Jupyter Notebook非常适合数据科学和分析。以下是如何在Jupyter Notebook中导入CSV文件的具体步骤:
1)启动Jupyter Notebook
在Anaconda Navigator中启动Jupyter Notebook或通过终端输入命令“jupyter notebook”启动。
2)新建Notebook文件
进入Jupyter Notebook后,点击右上角的“New”,选择Notebook。
3)编写代码导入CSV文件
在新建的Notebook文件中,输入上文介绍的导入数据集代码,导入csv文件。
3)运行代码
点击顶部“运行”按钮(或按下Shift+Enter),执行代码。
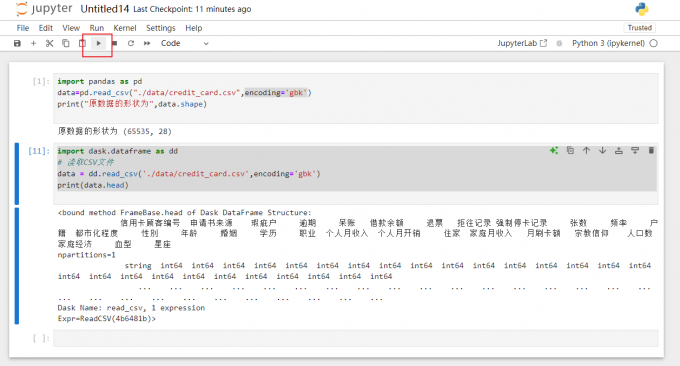
2、使用Spyder导入CSV文件
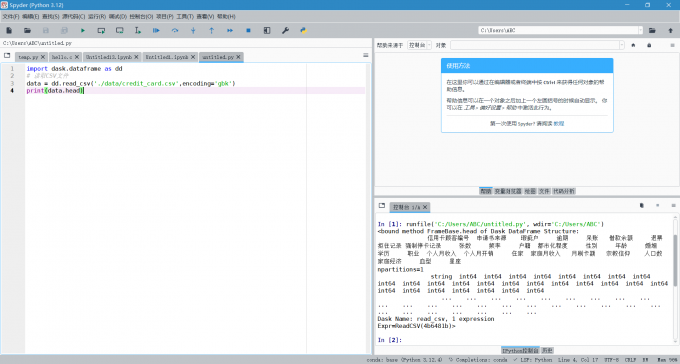
Spyder是Anaconda中的另一个开发工具,以下是使用Spyder导入CSV文件的步骤:
1)启动Spyder
在开始菜单或者Anaconda Navigator中启动Spyder。
2)编写导入CSV文件的代码
在Spyder中输入导入CSV文件的代码,例如上文介绍的Dask处理大型数据集代码。
3)运行代码
点击菜单栏上的“Run”按钮或按F5键执行代码,并显示CSV文件的数据。
三、总结
以上就是Anaconda如何导入数据集,Anaconda怎么导入CSV文件的相关内容。本文介绍了在Anaconda中导入数据集的常见方法,包括使用Pandas库和Dask库导入不同类型的数据。同时,还介绍了如何在Jupyter Notebook和Spyder中导入CSV文件的具体步骤。希望本文内容对你有所帮助。
署名:Hungry
